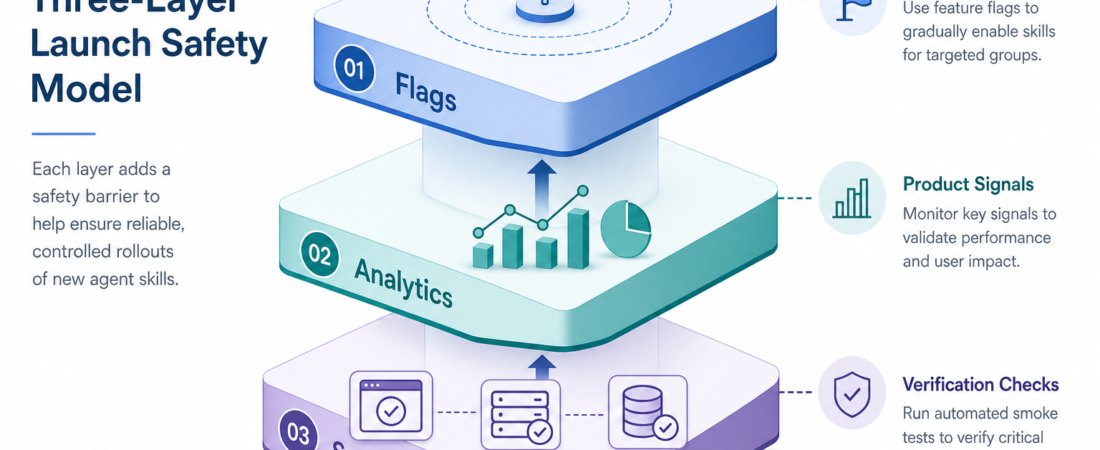
Feature Flags, Analytics, and Smoke Tests: The Three-Layer Launch Safety Model
Most launch failures are not caused by one missing test. They happen because a team treats “release” as a single gate instead of a controlled operating model.
A product can pass unit tests and still fail for a real segment. A feature flag can limit blast radius and still hide a broken checkout path. Analytics can show a drop in conversion and still leave the team guessing about the user journey that broke. Smoke tests can confirm the happy path and still miss the bad rollout rule that exposed beta behavior to the wrong account tier.
The practical answer is not one bigger checklist. It is three layers that do different jobs: feature flags control exposure, analytics and session replay observe behavior, and smoke tests verify critical flows. When those layers are encoded as agent skills, release work becomes less dependent on memory and more dependent on repeatable evidence.
Layer 1
Control Exposure
Flags decide who sees the change, how fast rollout expands, and how quickly the team can pause or roll back.
Layer 2
Observe Behavior
Analytics and replay show what changed after exposure: conversion, errors, friction, latency, and user paths.
Layer 3
Verify Flows
Smoke tests prove critical paths still work before rollout, during rollout, and after the release reaches more users.
Layer 1: feature flags control blast radius
Feature flags are often sold as a deployment convenience, but their real value is operational control. They let a team separate code deployment from product exposure. That matters because modern launches rarely fail uniformly. They fail for a plan tier, geography, browser, tenant, integration, pricing path, or data shape that was underrepresented in staging.
The first layer of the launch safety model asks: who should see this change, under what conditions, and what is the rollback rule?
Agent skills are useful here because flag work is easy to get almost right. A person can remember the intended audience and still miss an environment, default variation, dependency flag, or stale targeting rule. A release agent using a skill like Design and verify LaunchDarkly feature-flag targeting and rollout changes with MCP safety checks can inspect the rollout plan, summarize the targeting logic, and verify that the planned exposure matches the release note. For open-source flag infrastructure, Flagsmith Open Source Feature Flag and Remote Config Platform gives teams a similar control layer without tying the workflow to one commercial vendor.
The important habit is to treat a flag as a release contract, not just a toggle. A useful contract includes the target cohort, the starting percentage, the expansion schedule, the owner, the metrics to watch, and the exact rollback trigger. If any of those are missing, the launch is still being carried by tribal memory.
Layer 2: analytics show whether users are succeeding
Flags tell you who was exposed. They do not tell you whether the exposed users succeeded. That is the second layer: product analytics, event streams, funnels, and session replay.
This layer is where many teams either underreact or overreact. A dashboard may show a conversion dip, but the cause could be seasonality, a tracking change, a browser-specific bug, a pricing experiment, or a broken event name. An agent should not declare a launch good or bad from one metric. It should assemble a short evidence packet: what changed, which segment changed, how large the signal is, whether errors moved with it, and whether individual sessions confirm the story.
Skills like PostHog Product Analytics and Feature Flags SDK are especially interesting because flags and analytics can live close together. That lets a workflow compare exposed and unexposed cohorts instead of treating the whole product as one population. For teams that need session-level context, OpenReplay Self-Hosted Session Replay and Product Analytics Platform and the more focused Browser Session Replay Analyzer help an agent move from the funnel dropped to users are looping on this step after the new validation message appears.
This is where launch agents should stay modest. Analytics can identify correlations and narrow the search space; it should not invent causality. The best output is usually a bounded readout: the segments affected, the strongest supporting evidence, the gaps in instrumentation, and the recommendation to continue, pause, rollback, or investigate before expanding.
Layer 3: smoke tests prove critical paths still work
The third layer is active verification. Smoke tests answer a different question from analytics: can the product still perform the flows the team considers essential?
A good smoke test set is smaller than a regression suite and more serious than a status ping. It should cover the core paths that would make a release unacceptable if broken: sign in, create or edit the key object, complete checkout, send the message, generate the report, export the file, or connect the integration. It should run against the same environment and flags that users will hit, not a comforting parallel universe.
For browser-heavy flows, Drive token-efficient browser testing from coding agents with Playwright CLI, Run browser and API automation through the Playwright MCP server, and Verify local web apps with Playwright scripts and managed dev servers give agents a way to click through real UI behavior and return evidence rather than confidence. For API and scheduled checks, Checkly CLI Monitoring as Code for API and Browser Checks and httpYac request-file checks are better fits than forcing every verification through a browser.
The point is not to automate every possible path. The point is to encode the few checks that would make the release decision change. A launch agent should be able to say: these flows passed, this one failed with a screenshot or response body, and therefore the rollout should not expand.
Why the layers work better together
Each layer has a blind spot. Feature flags can limit damage but cannot prove quality. Analytics can detect behavior but may lag or mislead. Smoke tests can prove known flows but miss unknown user behavior. Together, they form a practical release model.
Before launch, an agent can verify that the flag is scoped correctly, run smoke checks against the flagged experience, and confirm that the dashboards or events needed for monitoring exist. During launch, it can compare exposed and unexposed cohorts, watch error and funnel movement, and rerun smoke tests when the rollout percentage changes. After launch, it can produce a short release note with what shipped, what evidence was checked, what changed in the metrics, and whether any follow-up is needed.
This is also where agent skills beat loose prompts. A prompt can ask an assistant to check the launch, but a skill can encode the real workflow: inspect flags, query analytics, run specific checks, collect artifacts, and stop before it takes risky action. That matches the ASE view of useful automation: the agent prepares evidence and recommendations; humans still own the product decision when the stakes are high.
A practical rollout playbook
For teams building this pattern, start small. Pick one upcoming feature and write a launch packet before release. Include the target cohort, the flag plan, the three to five product metrics that should move or stay stable, the smoke tests that must pass, and the rollback criteria.
Then assign each layer to a skill-backed workflow. The flag workflow checks targeting and defaults. The analytics workflow creates the baseline and post-launch comparison. The smoke-test workflow runs the critical paths and stores artifacts. Keep the outputs short enough that a release lead can scan them in two minutes.
A strong launch packet usually contains six things:
- The change being released and the owner accountable for the decision.
- The flag or rollout mechanism, including cohort, percentage, and expansion schedule.
- The expected user behavior and the metrics that would confirm or challenge it.
- The smoke checks that must pass before exposure expands.
- The rollback or pause criteria, written before the launch starts.
- The evidence collected after launch: screenshots, traces, dashboard links, session examples, and failed-check details.
This structure keeps agents away from the weakest version of launch automation: a long cheerful summary after the damage is already done. The useful agent is more boring and more valuable. It checks the control plane, reads the signals, runs the flows, and tells the team where the evidence is strong or thin.
What still needs human judgment
Even a well-instrumented launch model does not remove product judgment. A metric can move for reasons the agent cannot understand. A small cohort can include a high-value customer. A smoke test can pass while the new experience feels confusing. A session replay can reveal friction that is acceptable for a beta but unacceptable for a broad rollout.
That is why the model should end with a recommendation, not an autonomous expansion. Agents can prepare the release lead to make a faster, better decision. They can also block obvious mistakes: a flag with the wrong default, a dashboard missing the key event, a broken checkout path, or a rollout that expanded without the agreed smoke checks. But the final call still belongs to the team responsible for customer impact.
The best launch safety model is not dramatic. It is repeatable. Control exposure with flags. Observe real behavior with analytics and replay. Verify critical flows with smoke tests. Then make the rollout decision from evidence, not hope.